From Memory to Photonics: Solving the Next Bottleneck in AI Scaling
In the previous post, I looked at FlashAttention as an example of IO-aware algorithm design.
The important lesson was not simply “FlashAttention is faster.” The deeper lesson was that the same mathematical equation can behave very differently depending on how data moves through hardware.
Naive attention writes large intermediate tensors to HBM. FlashAttention avoids materializing those tensors, streams over tiles, keeps online softmax statistics, and recomputes what it needs later.
So FlashAttention is not fixing memory hardware.
It is adapting the algorithm to the memory hierarchy that already exists.
This post zooms out from memory movement inside one device to communication between many devices.
Once a model scales beyond one accelerator, we are no longer only asking how data moves between device memory, on-chip memory, registers, and matmul units. We are also asking how data moves across devices, servers, and racks.
That is where photonics starts to matter.
The physical bottleneck is still there
FlashAttention is a good reminder that software can do a lot.
But it does not remove the underlying physical constraint. An accelerator still has registers, on-chip SRAM / scratchpad memory, caches, and HBM or other device memory. Data still has to move between them. That movement costs time and energy.
At this level, engineers worry about things like:
- HBM traffic
- on-chip SRAM / scratchpad / shared-memory usage
- register pressure
- cache behavior
- occupancy
- kernel scheduling
- whether a kernel is compute-bound or memory-bound
The raw matmul engines are extremely fast and heavily optimized. This does not mean matmul is never the bottleneck. If a kernel has high arithmetic intensity and enough data reuse, it can absolutely become compute-bound.
But as systems scale, the uncomfortable question often shifts from:
Can we do the multiply?
to:
Can we feed the multiply and coordinate all the devices?
This is why arithmetic intensity and roofline models are useful. A roofline picture forces us to ask how much useful math we get per byte moved, and whether runtime is limited by compute throughput, memory bandwidth, communication bandwidth, or capacity. The JAX scaling book roofline chapter gives a nice version of this framing.
The short version is:
FlashAttention mostly lives in the second box. It reduces unnecessary memory traffic inside the device.
Photonics mostly enters through the third box: communication.
Now zoom out to hyperscale
Training and serving large models often involve many accelerators connected together: inside one server, across racks, and sometimes across whole data-center campuses.
At that scale, communication becomes part of the model runtime.
Some examples:
- tensor parallelism moves intermediate activations between devices
- data parallelism synchronizes gradients
- pipeline parallelism sends activations between stages
- MoE models create all-to-all routing patterns
- inference may shard weights or KV cache across devices
This is not just “networking” as a separate IT topic. For large models, communication can sit directly in the critical path of training or inference.
Inside one accelerator, the question was local memory traffic.
Across many accelerators, the question becomes communication.
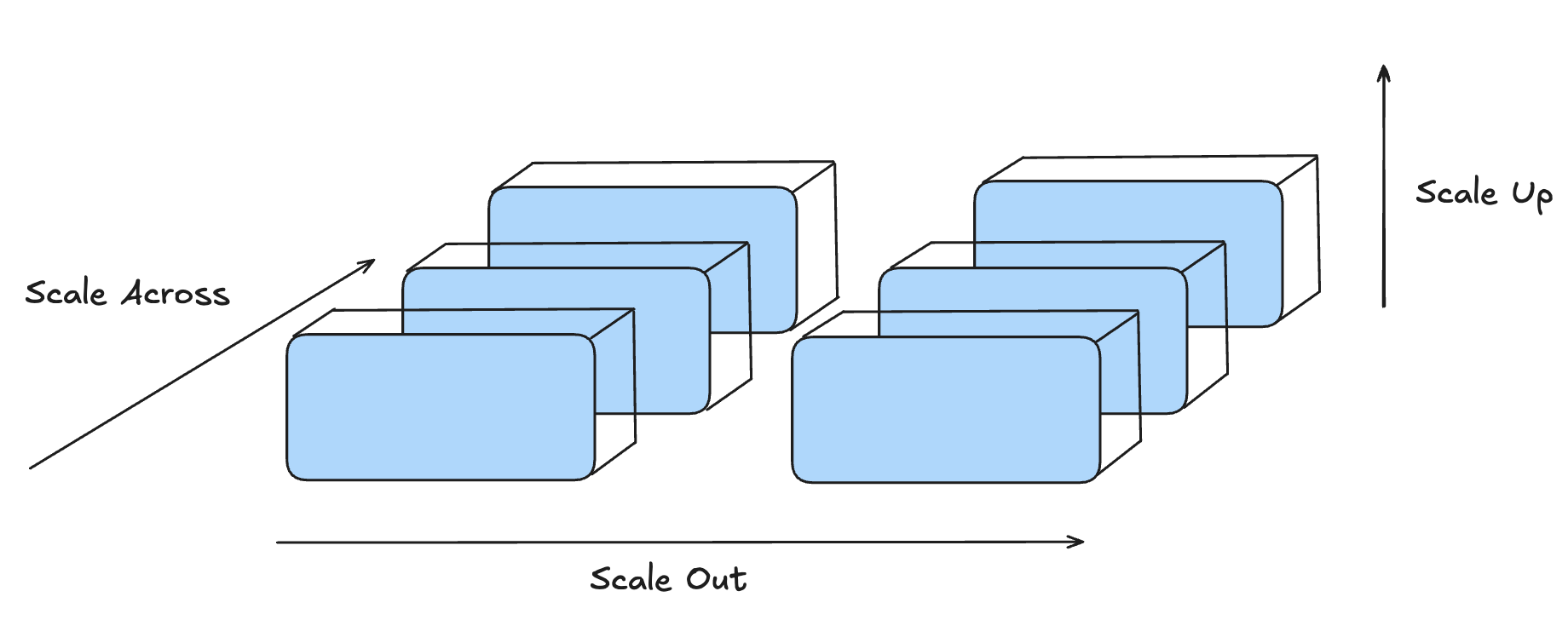
Scale-up, scale-out, and scale-across are different versions of the same pressure: more compute nodes need more links.
To visualize how big this can get, some proposed AI data-center campuses are being discussed at almost city-like scale. One reported example is the Stratos project in Utah, which has been described as a 40,000-acre campus, roughly 162 km2 (The Verge). ICML 2026 is taking place in Seoul (ICML 2026), and Seoul proper is about 605 km2 (Seoul).
That is roughly one quarter of Seoul.

Seoul compared with the reported Stratos footprint.
I do not want to make too much out of one proposed project. Not every AI data center will look like this, and reported plans can change.
But even this rough scale makes the point: as AI systems get physically larger, moving data between machines becomes harder to ignore.
Copper is useful, but the tradeoff gets painful
Many short electrical links are copper-based. Copper is not bad.
Copper is useful for a reason: short distance, low cost, mature manufacturing, familiar packaging, and practical deployment.
The problem is that high-bandwidth, longer-distance communication becomes increasingly expensive in power and heat.
As bandwidth and distance increase, copper runs into a bandwidth-distance-power tradeoff. High-speed copper links often need stronger signaling, equalization, retimers, and more power to preserve signal integrity. More power becomes more heat. More heat becomes a cooling and reliability problem.
This does not mean copper disappears. It means copper becomes less attractive when bandwidth, distance, density, and energy efficiency all have to improve at the same time.
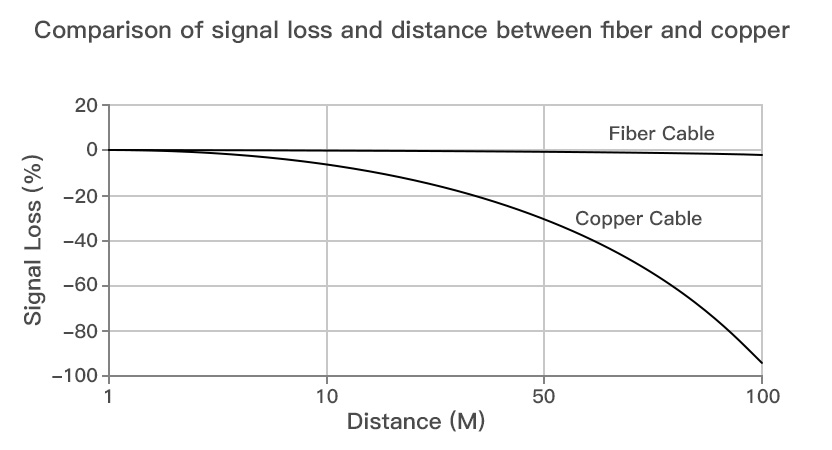
A simple fiber/copper loss comparison over distance (source).
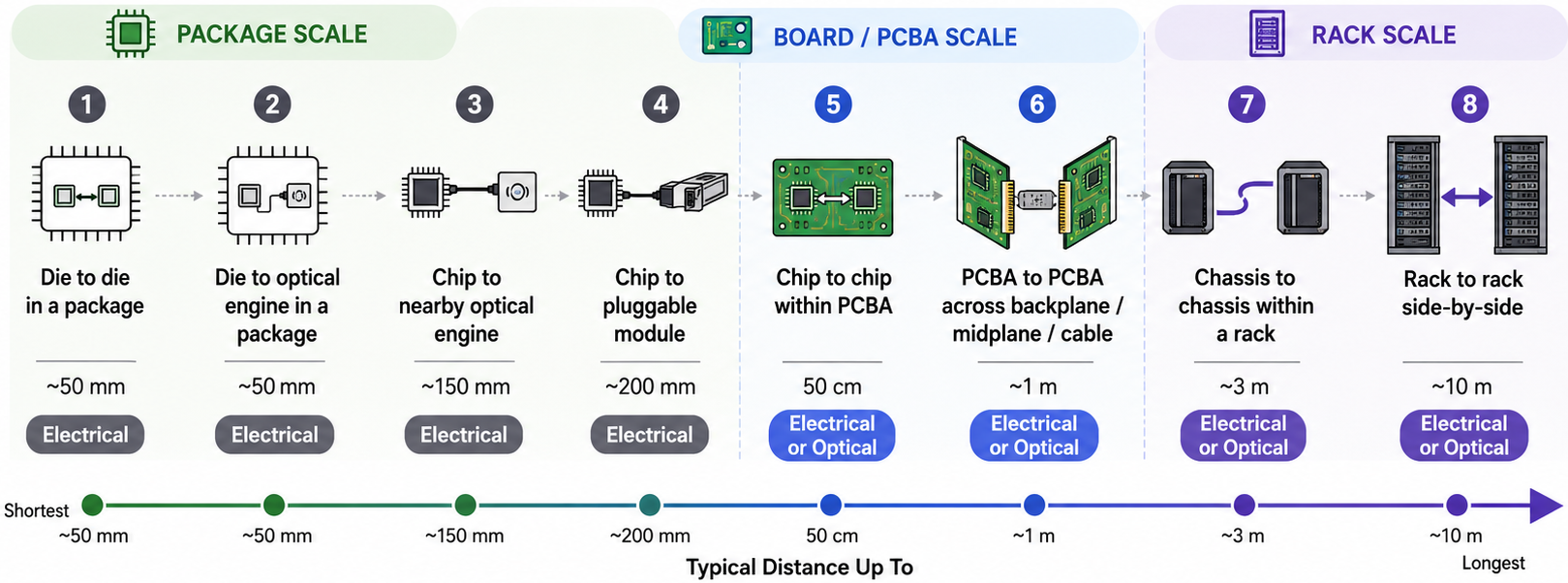
Interconnect distances from OIF's Next Generation CEI-224G Framework, Table 4 (source).
This is also why I am careful when I see simple market stories like “AI means buy copper” or “AI means buy natural resources.”
That story can be economically relevant. Data centers do use a lot of physical material. Copper demand can matter.
But from a hardware-systems perspective, copper is also one of the places where scaling pressure shows up. If the system needs more bandwidth over longer distances with lower energy per bit, optics becomes more attractive.
The point is not “copper is wrong.”
The point is:
short, cheap, electrical links: copper is very good
longer, denser, higher-bandwidth links: optics becomes more important
There is also a subtle latency point here.
Optics is not interesting just because “light is fast.” Electrical signals in copper also propagate at a significant fraction of the speed of light. For many AI interconnect discussions, the bigger practical wins are bandwidth density, reach, signal integrity, and energy per bit.
That is the less catchy version of the story, but it is the one I find more useful.
Heat is not only a chip problem
Heat is easy to think of as a chip-level problem:
accelerator gets hot
rack needs cooling
data center needs power
But at AI infrastructure scale, heat becomes environmental too.
Data centers convert huge amounts of electrical power into waste heat, and that heat has to go somewhere. We now see headlines like “Data centers raise temperatures up to 4 degrees in nearby neighborhoods: study”.
The Facilities Dive article discusses a Phoenix-area study where air-cooled data centers were associated with downwind temperature increases in nearby neighborhoods. I do not read that as “copper wires are heating neighborhoods.” That would be the wrong causal story.
The point is broader:
This is why I keep coming back to movement.
Not just:
How many FLOPs can we buy?
but:
How much data has to move?
How far does it move?
How much energy is spent per bit?
Where does the heat go?
This is the connection between FlashAttention and photonics: FlashAttention asks us to stop moving unnecessary intermediate tensors through HBM, while photonics asks whether the physical interconnect itself should change when the system gets large enough.
Photonics: yes, light, not electricity
This is where photonics enters.
Instead of sending information only as electrical signals through copper, optical communication sends information as light through fiber or optical waveguides.
The basic path is:
electrical signal -> optical signal -> fiber/waveguide -> electrical signal
The conversion happens through optical transceivers or optical engines.
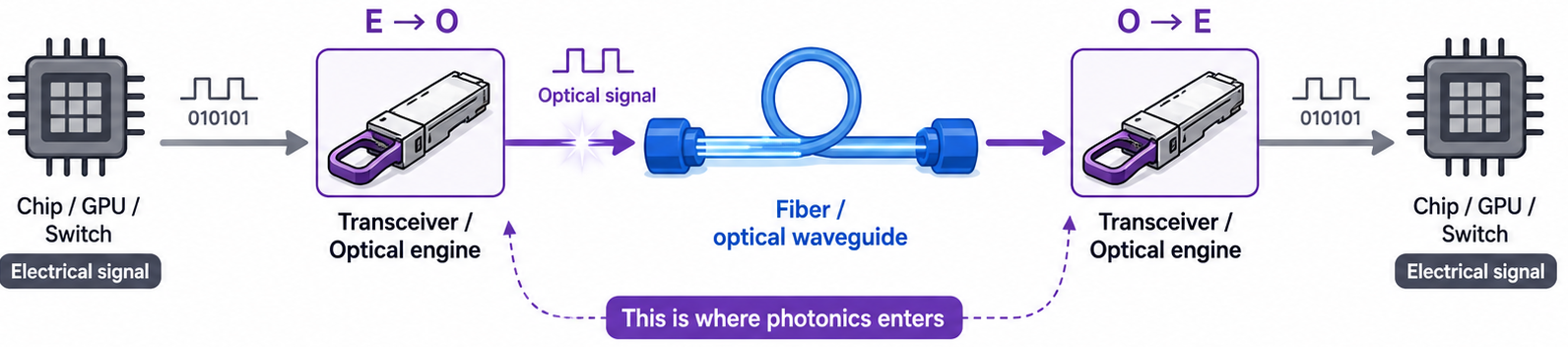
Electrical signal to optical link and back.
There are two important pieces:
- Optical transceiver / optical engine: converts electrical signals to optical signals and back.
- Optical fiber / waveguide: carries the optical signal.
Companies like Lumentum, Coherent, Broadcom, Marvell, and others participate in the transceiver / optical-engine ecosystem. Corning is one major company associated with optical fiber.
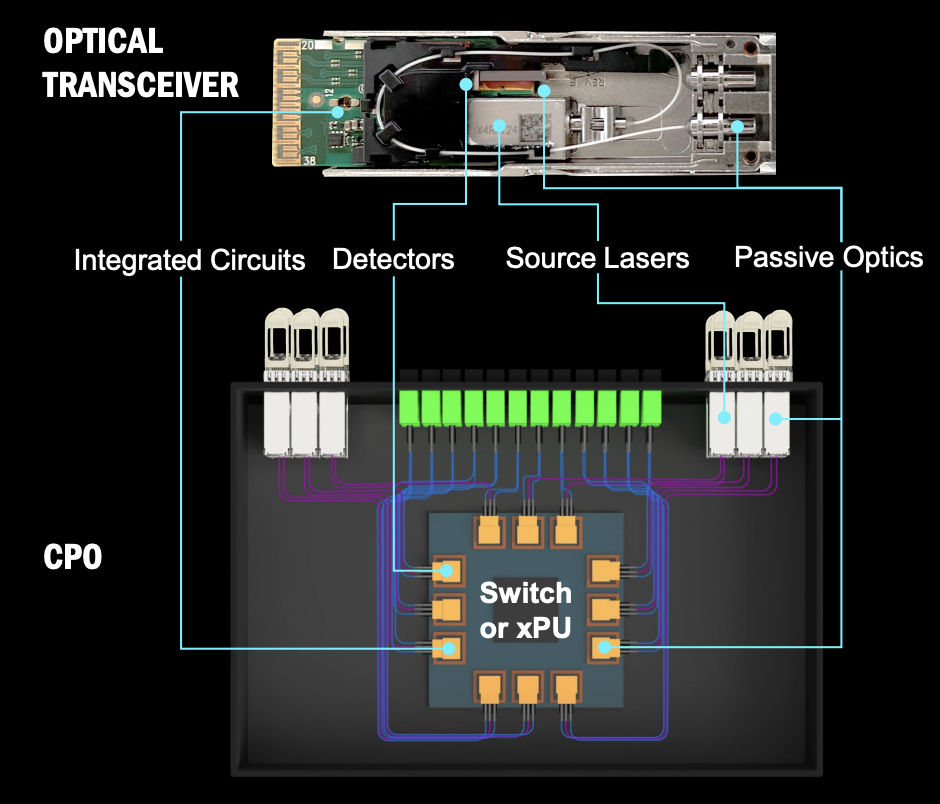
Optical transceiver and co-packaged optics view, from Coherent's March 17, 2026 briefing (PDF).
This is also where the story becomes more interesting than just “replace copper cables with fiber.”
Data centers already use optical fiber heavily, especially for longer reaches. The newer pressure is about moving optics closer to compute: from pluggable modules, to optical engines near switch ASICs, to co-packaged optics, and maybe eventually to optical I/O closer to accelerator packages.
That does not mean all links become optical overnight.
It means the electrical-to-optical boundary may move closer to the chips as bandwidth and energy pressure increase.
Also, this post is about optical communication, not replacing matmul units with optical computing.
That distinction matters.
The accelerator still does the matrix multiplication, whether that accelerator is a GPU, TPU, or something else. Photonics is mostly about moving data between compute elements more efficiently.
Which layer does photonics actually change?
This was the part that confused me at first.
When people say photonics matters for AI, it can sound like photonics is replacing the accelerator. That is not the main story here.
Photonics does not directly replace HBM, on-chip memory, registers, or matmul units.
It mostly changes the interconnect layer.
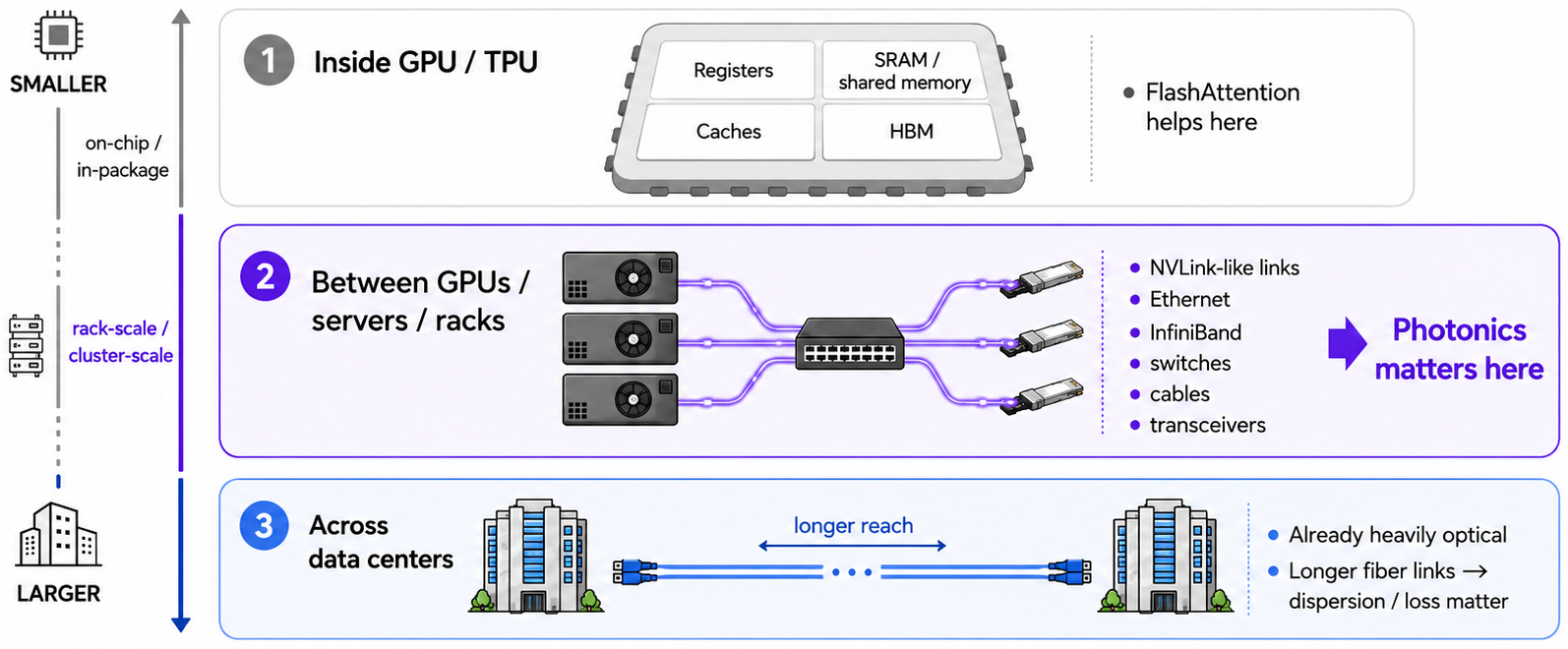
Where FlashAttention and photonics sit in the system stack, using OIF CEI-224G interconnect layers (source).
The useful distinction is scale.
Inside one accelerator, FlashAttention is about the local memory hierarchy: device memory, on-chip memory, caches, registers, and the matmul units doing the work.
Between devices, servers, and racks, the relevant objects change. Now we are talking about NVLink-like links, Ethernet or InfiniBand fabrics, switches, cables, and transceivers. This is the layer where photonics increasingly matters.
Across data centers, fiber is already the normal story, although longer reach brings its own loss, dispersion, and networking constraints.
So the short comparison is simple: FlashAttention is IO-aware software inside the device. Photonics is communication-aware infrastructure between devices and systems.
This distinction also keeps us honest.
Photonics is not the answer to every link at every scale. Very short links can still be better served electrically because the conversion overhead, packaging cost, thermal constraints, and integration complexity may not be worth it.
The interesting part is the boundary.
Where should the system stop being electrical and become optical?
That boundary is moving.
Why this matters for AI scaling
As AI models and clusters scale, the system becomes less like one big computer doing math and more like many devices passing tensors back and forth.
The matmul units may be ready to multiply. But the system still has to deliver the right tensors to the right device at the right time.
That makes communication a first-class bottleneck.
We can attack this from the software side:
- better sharding
- better scheduling
- communication overlap
- kernel fusion
- topology-aware parallelism
- IO-aware algorithms like FlashAttention
But as clusters grow, the physical interconnect itself starts to matter.
This is why photonics matters: AI scaling keeps turning compute problems into movement problems.
memory movement
network movement
heat movement
energy movement
So the hardware story is not only faster compute. It is also less-wasteful movement.
Where our work fits
If photonics becomes a more important part of AI infrastructure, then designing photonic components becomes more important too.
But photonic design is not always intuitive.
The design space can be high-dimensional, physics-constrained, and hard to interpret. A small geometric change can alter interference, coupling, loss, bandwidth, fabrication robustness, or wavelength response. It is not always obvious from the final shape why a design works.
This is why inverse design is useful in silicon photonics. Many of the building blocks we care about, such as splitters, couplers, mode converters, and filters, need to be compact and efficient while still respecting fabrication and physics constraints.
This is the part closer to our own work.
We are interested in methods that do not only generate designs, but also help us understand why those designs work.
In other words:
design capability + interpretability
That combination matters because photonics is not just another black-box optimization problem. If photonic devices are going to sit closer to AI infrastructure, we need tools that respect both the physics and the engineering constraints.
If this direction is interesting, come see our poster at ICML AI4Physics.
References
- Training a Language Model from Scratch (Part 2: FlashAttention and Device Memory)
- JAX Scaling Book: Roofline
- ICML 2026 official conference page
- Seoul: city area
- The Verge: The biggest data center ever is becoming a huge problem in Utah
- Facilities Dive: Data centers raise temperatures up to 4 degrees in nearby neighborhoods: study
- OIF: Next Generation CEI-224G Framework
- Coherent: Technology Innovation Briefing, March 17, 2026
- FastCabling: Extend WiFi with WiFi 6 access point using fiber optic cable
Enjoy Reading This Article?
Here are some more articles you might like to read next: