Training a Language Model from Scratch (Part 2: FlashAttention and Device Memory)
In the previous blog post, I went over the basic building blocks of the language model: tokenization, embeddings, RoPE, attention, etc.
But if I zoom into the attention part, the previous post mostly treated it as a clean equation:
\[O = \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V\]That is the right mathematical object, but it hides a systems question: what actually happens when the computer tries to run this equation?
This post is about that missing layer. Not just “what is attention?”, but why naive attention becomes memory-heavy, why softmax can be slower than the FLOP count makes it look, and why FlashAttention is such a nice algorithmic trick.
Profiling first
Some things we can observe from a profiling timeline:
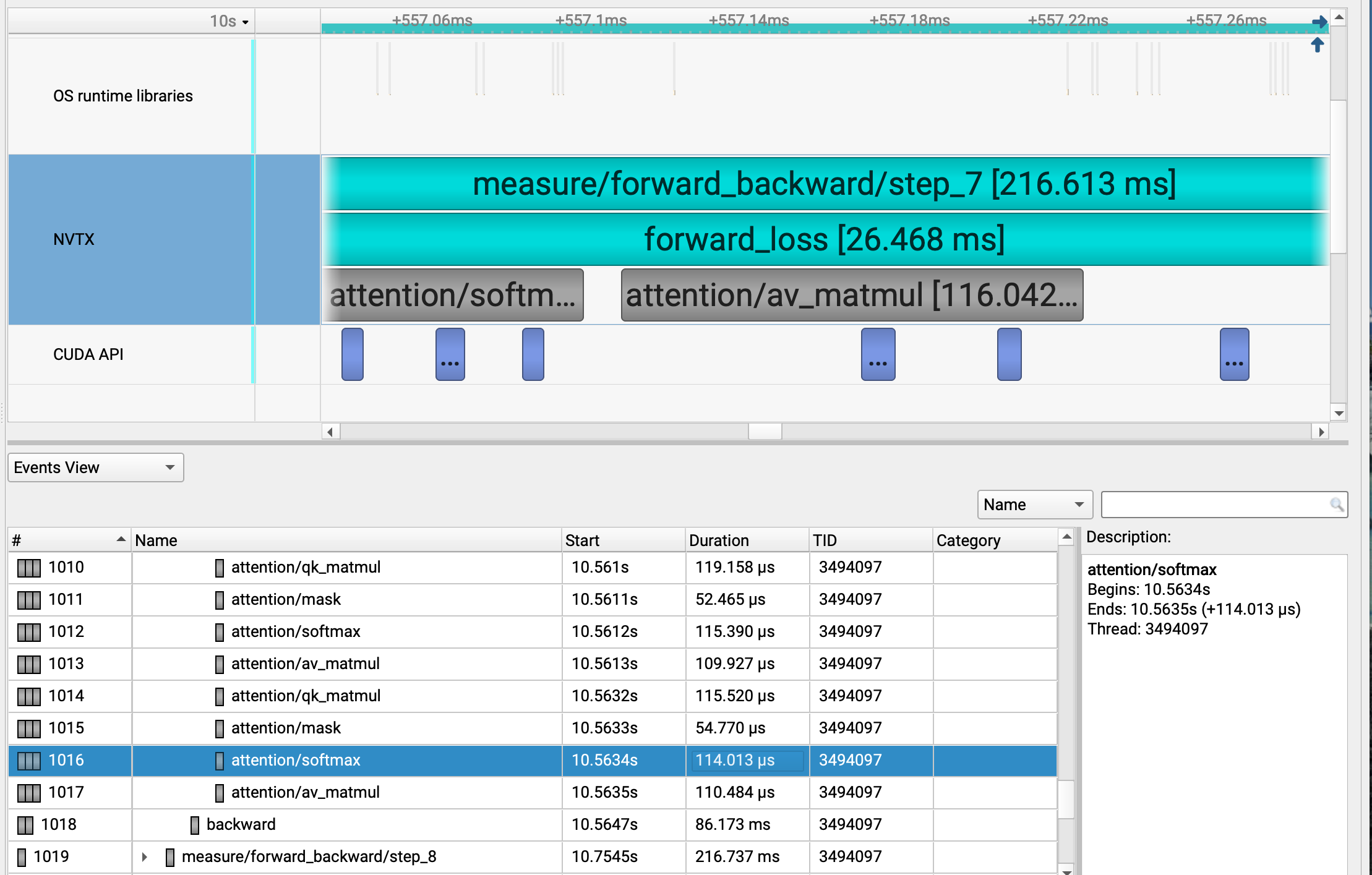
Profiling shows that attention is not only matmul. Softmax can take a meaningful part of the timeline even though its FLOP count is much smaller than the matmuls.
The first useful split is that “expensive” is not one word.
For FLOPs, the obvious large operations are matrix multiplications. In attention, those are:
\[QK^\top\]and:
\[PV\]where:
\[P = \operatorname{softmax}(S), \quad S = \frac{QK^\top}{\sqrt{d}}\]But wall-clock time is not only FLOPs. Operations like softmax can take a surprisingly long time because they are reduction-heavy and memory-traffic-heavy. Stable softmax has to scan a row for the max, exponentiate, sum, divide, and write the result. Also, those operations are not the nice specialized GEMM work that accelerators are extremely good at.
So, like traditional algorithms, we have two axes:
- Speed
- Memory
And for attention, memory becomes especially painful because naive attention materializes matrices shaped like:
\[[B, H, N, N]\]where $N$ is the sequence length. That $N^2$ is the part that quietly turns long context into a problem.
Before FlashAttention
Before going into FlashAttention, there are a few common techniques that show up everywhere.
Mixed precision
Details
Mixed precision uses lower precision where it is usually safe and faster, while keeping more sensitive operations in higher precision.
For example, matmuls can often use FP16/BF16 to use specialized matmul units and lower memory bandwidth. But reductions, normalization, losses, optimizer state, and long accumulations often need more care.
The point is not “make everything lower precision.” The point is strategic precision.
Operator fusion
Details
Operator fusion combines several operations into one kernel.
If we do:
x = x - x.max(dim=-1, keepdim=True).values
num = torch.exp(x)
den = num.sum(dim=-1, keepdim=True)
y = num / den
a naive implementation might read and write intermediate tensors between each step. A fused implementation can keep more of the work inside the kernel and reduce memory traffic.
This is one reason softmax is a good example. The arithmetic is not that scary, but repeatedly writing and reading the intermediate rows is wasteful.
Recomputation / checkpointing
Details
Autograd normally saves tensors during forward because backward will need them later.
Checkpointing changes the tradeoff: save fewer intermediate tensors, and recompute the missing values during backward.
So the tradeoff is:
\[\text{less memory} \quad \leftrightarrow \quad \text{more compute}\]This idea will come back in FlashAttention backward. Instead of saving the giant $S$ and $P$ matrices, we save enough information to recompute the necessary probability blocks later.
The missing idea: IO-awareness
The techniques above are useful, but by themselves they are not fully IO-aware.
By IO-aware, I mean: the algorithm explicitly cares about how many times data moves between different levels of memory.
At a high level, the relevant memory hierarchy is:
For FlashAttention, the main game is reducing traffic between HBM and the on-chip levels above it.
A kitchen analogy
The key point is that we want to access HBM as little as possible and do as much work as possible while the relevant tiles are already in on-chip memory.
Imagine a chef making beef soup.
The storage room is HBM. The kitchen table is on-chip SRAM/shared memory. The chef’s hands are registers.
If the chef had to walk to the storage room after every tiny step, it would be terrible. Chop one vegetable, walk back and store it. Bring it out again. Add salt, walk back again. Take it out again. The chef’s feet would be burning at this point.
The natural question is: why not bring everything into the kitchen at once?
Because the kitchen is small, and the door is narrow.
In more concrete terms, the accelerator cannot fit the entire attention matrix in fast on-chip memory. It has to move tiles through registers/shared memory while the full tensors live in HBM.
That is basically the attention problem. In naive attention, we bring big chunks of Q, K, and V, compute the full $QK^\top$ matrix, write that to HBM, read it back for softmax, write probabilities back, read them again, then multiply by V.
For the notation below, I sometimes write $QK^\top$ without the $1/\sqrt{d}$ scale. The scale is still part of real attention.
The math is clean:
\[S = QK^\top\] \[P = \operatorname{softmax}(S)\] \[O = PV\]But the memory movement is ugly:
compute S -> write S to HBM
read S -> compute P -> write P to HBM
read P and V -> compute O -> write O
FlashAttention asks: can we avoid this back and forth?
FlashAttention in a nutshell
FlashAttention combines tiling, online softmax, and recomputation.
It does not approximate attention. The output is still:
\[\operatorname{softmax}(QK^\top / \sqrt{d})V\]The difference is how the algorithm is scheduled.
Instead of materializing the full $S$ and $P$ matrices in HBM, FlashAttention:
- Loads a tile of Q.
- Streams over tiles of K and V.
- Computes local score blocks.
- Maintains running softmax statistics per query row.
- Accumulates the output numerator.
- Writes only the final output and a small log-sum-exp vector.
In FlashAttention-2, the forward pass uses an outer loop over Q row blocks and an inner loop over K/V column blocks. The original FlashAttention paper also used tiling, but FlashAttention-2 changed the loop order and work partitioning to improve parallelism and reduce unnecessary shared-memory traffic.
Original attention vs FlashAttention-2 tiling
The easiest way to understand this is to visualize the matrix multiplications.
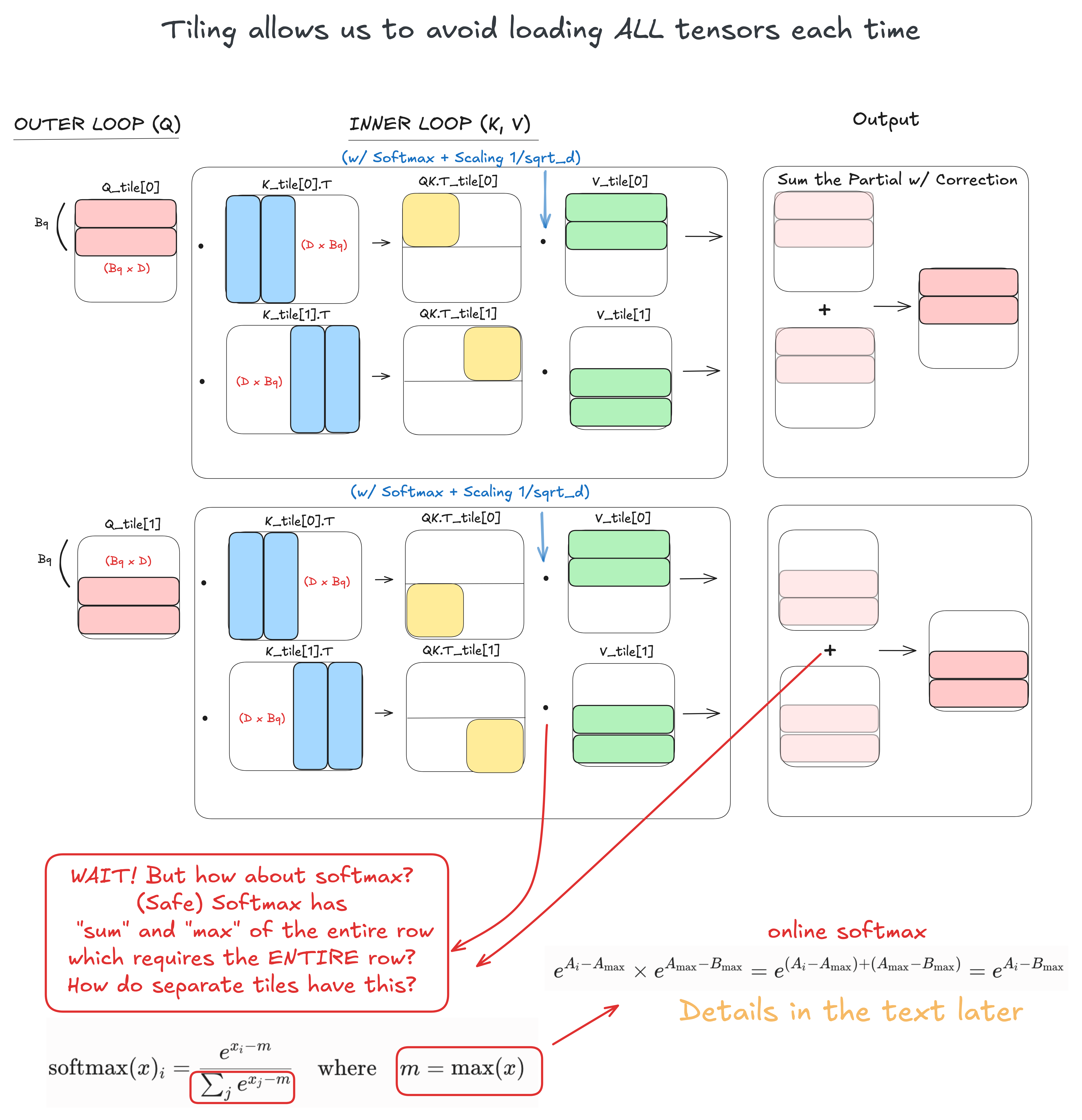
FlashAttention splits attention into row/column tile work instead of materializing the whole attention matrix. The output-side accumulation still needs online-softmax correction.
Conceptually, $QK^\top$ computes how much each query token attends to each key token. For a fixed query row, the softmax weights are spread across all key positions, and the output is a weighted sum of the matching V rows.
So we can split this row-wise work into chunks:
Q block i attends to K/V block 0
Q block i attends to K/V block 1
Q block i attends to K/V block 2
...
The problem is that softmax couples the entire row. We cannot just softmax each block independently and concatenate the answers. The denominator of softmax needs the whole row.
That is where online softmax enters.
Accumulating the partial output
For one query block, each K/V block gives a partial contribution to the final output.
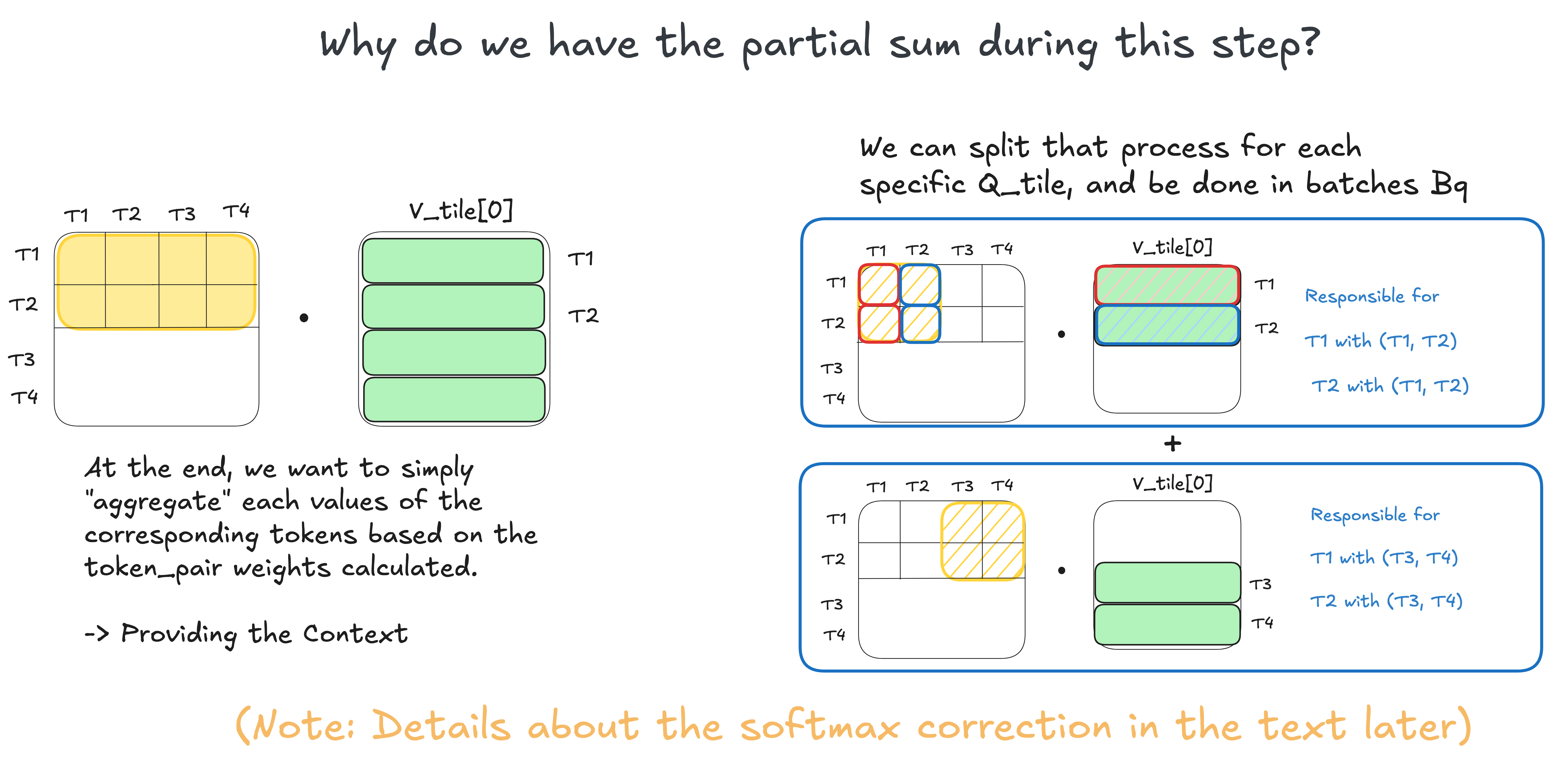
Each K/V tile contributes part of the final weighted sum. These partial contributions are rescaled with the running max and denominator before they are accumulated.
If the softmax denominator were not a problem, this would be easy:
\[O_i = \sum_j P_{ij}V_j\]Split over K/V blocks:
\[O_i = \sum_{j \in \text{block 0}} P_{ij}V_j + \sum_{j \in \text{block 1}} P_{ij}V_j + \cdots\]Safe / online softmax
Normally, stable softmax for one row is:
\[\operatorname{softmax}(x_j) = \frac{e^{x_j - m}}{\sum_t e^{x_t - m}}, \quad m = \max_t x_t\]This requires knowing the max of the entire row.
But suppose the row is split into tile A and tile B.
Tile A has max $m_A$. Tile B has max $m_B$. The global max is:
\[m = \max(m_A, m_B)\]If we processed tile A first using $m_A$, and later discover that $m_B$ is larger, the old tile A values were normalized with the wrong max. But this is fixable.
For an old value $x$ from tile A:
\[e^{x - m} = e^{x - m_A} \cdot e^{m_A - m}\]That tiny rescaling term is the whole trick:
\[e^{m_\text{old} - m_\text{new}}\]So as we stream over blocks, we keep:
\[m_i = \text{running row max}\] \[\ell_i = \text{running denominator}\] \[u_i = \text{running unnormalized output numerator}\]When a new block arrives:
\[m_\text{new} = \max(m_\text{old}, m_\text{block})\]Rescale the old denominator and numerator:
\[\ell_\text{new} = e^{m_\text{old}-m_\text{new}}\ell_\text{old} + \sum_{j \in \text{block}} e^{s_j - m_\text{new}}\] \[u_\text{new} = e^{m_\text{old}-m_\text{new}}u_\text{old} + \sum_{j \in \text{block}} e^{s_j - m_\text{new}}v_j\]At the end:
\[O_i = \frac{u_i}{\ell_i}\]That is the safe softmax trick in the streaming/tiled setting.
Connecting forward and backward with LSE
During backward, we do not want to have saved the full $S$ and $P$ matrices.
But we still need to recover $P$ blocks, because the gradient equations depend on softmax probabilities.
So what do we save?

FlashAttention saves one log-sum-exp value per query row. The $+m_i$ term is the row-max stabilization term; the recovered probability is $e^{S_{ij} - L_i}$.
The compact value is log-sum-exp:
\[L_i = \log \sum_t e^{S_{it}}\]For numerical stability, this is computed as:
\[L_i = m_i + \log \sum_t e^{S_{it} - m_i}\]where $m_i$ is the row max.
Then during backward, if we recompute a score tile:
\[S_{ij} = \frac{q_i^\top k_j}{\sqrt{d}}\]we can recover the softmax probability by:
\[P_{ij} = e^{S_{ij} - L_i}\]This is the key step. We do not need the full old probability matrix. We only need Q, K, V, the output O, the upstream gradient dO, and the row-wise $L_i$ values. Then we recompute the probability block when that tile is already loaded.
One detail that matters: $L_i$ is not “left part denominator and right part numerator.” It is the log of the full softmax denominator, written in a stabilized way. Subtracting $L_i$ from a score gives exactly score minus log-denominator, and exponentiating gives the softmax probability.
Backward pass
Now we have the building blocks for the backward pass.
Naive attention might save large intermediate tensors like $S$ and $P$. FlashAttention avoids saving them. It saves or has access to:
Q, K, V
O
LSE
dO
Then it recomputes $S$ and $P$ block by block.
Backward streams over tiles again. It recomputes score/probability blocks, accumulates dK/dV for a K/V block, and updates dQ for matching query blocks.
The conceptual order is:
- Recompute the local $P$ tile from $QK^\top$ and LSE.
- Use $P$ to compute $dV$ and $dP$.
- Use the softmax gradient to compute $dS$.
- Use $dS$ to compute $dQ$ and $dK$.
In matrix form, the main equations are:
\[S = \frac{QK^\top}{\sqrt{d}}\] \[P = e^{S - L}\]where $L$ is broadcast across the columns of each row.
\[dV = P^\top dO\] \[dP = dO V^\top\] \[dS = P \odot (dP - D)\]Here $D$ is a row-wise correction term, often computed from $dO$ and $O$. The important point is that this softmax-gradient line is elementwise, not a matrix multiplication by $P$.
\[dQ = \frac{dS K}{\sqrt{d}}\] \[dK = \frac{dS^\top Q}{\sqrt{d}}\]In the tiled backward pass, FlashAttention-2 conceptually flips the scheduling: it can hold a K/V block in the outer loop, stream through Q/dO/LSE/O blocks in the inner loop, accumulate dK and dV for that K/V block, and update dQ for each query block.
So:
outer loop: K/V block
inner loop: Q block
This feels natural because backward is going in reverse: we need to reconstruct the local $P$ block, use it to compute the local gradients, and aggregate the pieces.
Implementation notes: Triton
The next question is: how do we actually tell the computer to do this tiled movement?
PyTorch tensor code is great for expressing math, but it does not naturally give us control over “load this tile, keep this accumulator, avoid materializing this intermediate.” CUDA gives that control, but it is very low-level.
Triton sits in the middle. It gives a Python-like way to write GPU kernels where each program instance is basically a tile worker.
The Triton mental model:
| Triton concept | How I think about it |
|---|---|
grid | How many tile workers to launch. |
tl.program_id(axis) | The coordinate of the current tile worker. |
tl.arange | The row/column offsets inside one tile. |
tl.load / tl.store | Explicitly move tile data from/to global memory, usually with masks for boundary tiles. |
tl.dot | Do the tile matmul. |
In my naive forward kernel, the first grid axis chooses the Q tile, and the second grid axis chooses the batch:
pid_q = tl.program_id(axis=0) # which Q tile
pid_b = tl.program_id(axis=1) # which batch
q_rows = pid_q * BLOCK_M + tl.arange(0, BLOCK_M)
d_cols = tl.arange(0, BLOCK_D)
Then each program loads one Q tile:
q_ptrs = (
q_ptr
+ pid_b * stride_qb
+ q_rows[:, None] * stride_qn
+ d_cols[None, :] * stride_qd
)
q_tile = tl.load(
q_ptrs,
mask=(q_rows[:, None] < Nq) & (d_cols[None, :] < D),
other=0.0,
)
The kernel keeps the online softmax state in tile-shaped accumulators:
m = tl.full((BLOCK_M,), -float("inf"), tl.float32)
l = tl.full((BLOCK_M,), 0, tl.float32)
acc = tl.full((BLOCK_M, BLOCK_D), 0, tl.float32)
Then it streams over K/V blocks:
scores = tl.dot(q_tile, tl.trans(k_tile)) * scale
if IS_CAUSAL:
scores = tl.where(q_rows[:, None] >= k_rows[None, :], scores, -float("inf"))
m_old = m
m_tile = tl.max(scores, axis=1)
m_new = tl.maximum(m_old, m_tile)
probs = tl.exp(scores - m_new[:, None])
correct_term = tl.exp(m_old - m_new)
l = correct_term * l + tl.sum(probs, axis=1)
acc = acc * correct_term[:, None] + tl.dot(probs, v_tile)
m = m_new
Finally:
out_tile = acc / l[:, None]
lse_tile = m + tl.log(l)
This is not production FlashAttention. It is a scrappy version I scribbled for learning.
The limitations are still important:
- It is written for a simple shape like
[B, N, D], not a fully optimized[B, H, N, D]production layout. - Real kernels tune block sizes carefully.
- Real kernels have to care much more about dtypes, register pressure, shared memory, occupancy, causal masks, dropout, and backward.
There are definitely details I did not cover here. But writing this naive kernel made the main takeaway much clearer:
One last note on loop order
One detail that confused me at first was the loop order change from FlashAttention-1 to FlashAttention-2.
In FlashAttention-1, the forward pass roughly looked like:
for each K/V block:
load K_j, V_j
for each Q block:
load Q_i and the running O_i, m_i, l_i state
update the row-wise online softmax state
write O_i, m_i, l_i back
So if we imagine the attention matrix, this schedule moves through column blocks first. That does not mean online softmax becomes impossible. FlashAttention-1 still computes the row-wise max, denominator, and output exactly. The issue is more about where the running row state lives and how often we touch it.
For a given Q row block, the values $m_i$, $\ell_i$, and the output accumulator need to be updated as more K/V blocks arrive. With K/V in the outer loop, those row states are revisited across column blocks. If we want more parallelism across the sequence dimension, that schedule is awkward because each row’s final softmax state depends on all the column-block contributions being combined correctly.
FlashAttention-2 flips the forward schedule:
for each Q block:
keep m_i, l_i, and the output accumulator on-chip
for each K/V block:
update the row-wise online softmax state
write O_i and LSE_i once
This lines up better with the row-wise nature of softmax. Each worker owns a block of query rows, streams across K/V blocks, and only writes the final output and LSE for that row block at the end. The row blocks are independent, so the forward pass gets cleaner parallelism over the sequence dimension.
The backward pass has a different reduction shape. There, using K/V blocks in the outer loop is natural because $dK$ and $dV$ collect contributions from many Q blocks. So the “column-wise” feeling is not wrong. It is just serving a different accumulation pattern.
Main takeaway
The core lesson is not only “FlashAttention is faster.”
The deeper lesson is that the same mathematical equation can have very different system behavior depending on what intermediate tensors are materialized.
Naive attention says:
make S
make P
make O
FlashAttention says:
stream tiles
keep online softmax stats
accumulate O
save LSE
recompute P blocks in backward
Same exact attention. Different memory story.
That is why IO-awareness matters.
References
- Stanford CS336: Language Modeling from Scratch, Spring 2025 — Assignment 2: Systems
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- Triton fused softmax tutorial
- Triton
program_iddocumentation - Triton
loaddocumentation
Enjoy Reading This Article?
Here are some more articles you might like to read next: